✅ Tickets 2024-01 SCCM
Collection of tickets monthly
Time: 2024-01
Category: SCCM / MECM
I240109_0245 : MCO - Files stuck in Inbox folder
Issue: Monitor Inbox folders of MECM Site servers => NOK
There are too many files stuck in this folder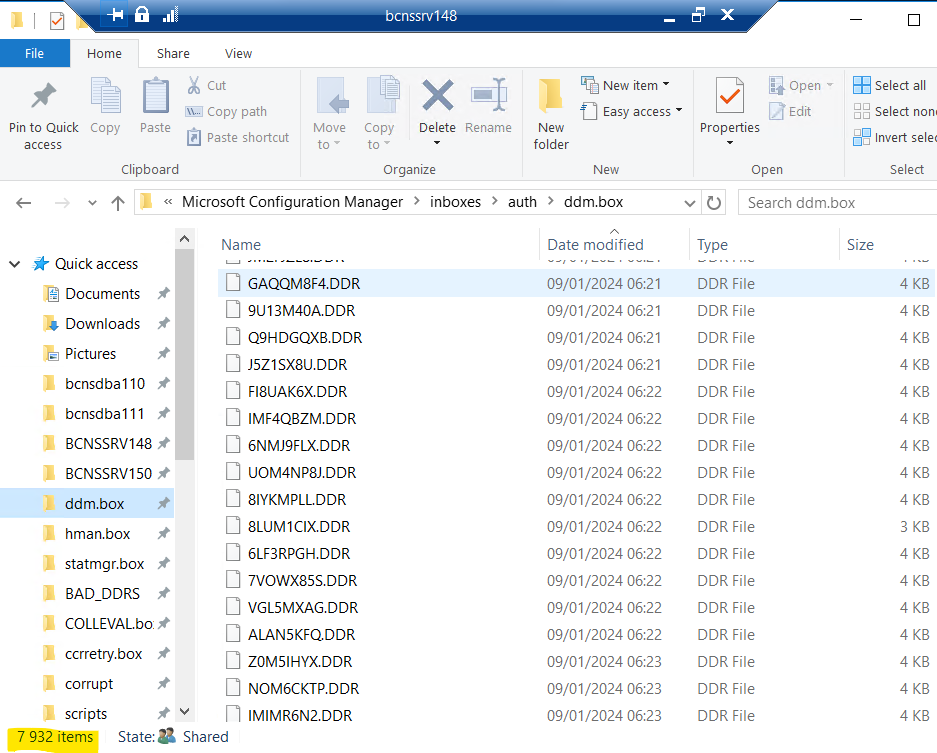
Solution: DATABASE plantée suite saturation CPU
I231214_0346 : MCO - Site and components health check NOK
Issue:
MCO - Site and components health check NOK
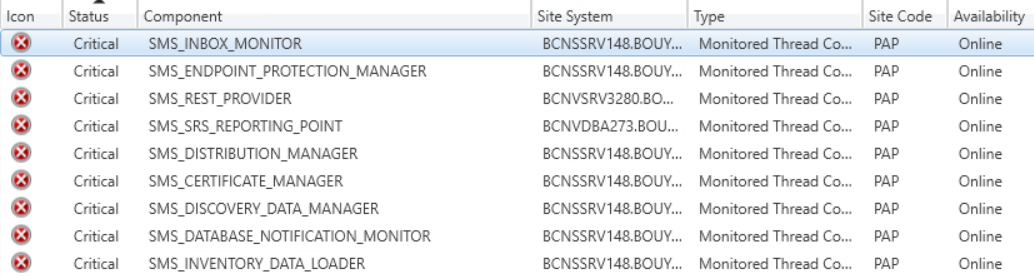
Solution:
La plupart des alertes ne sont plus actives (en partie dues au pic CPU sur la base SQLce matin).
J’ai activé le TLS 1.2 sur le nouveau serveur de report afin que le check du service RS puisse se faire
I231205_0242 : MCO - BADMIF exceed 300
- Issue:
Command get result larger than value 300 (Count : 329)1
Get-ChildItem -Path "E:\Microsoft Configuration Manager\inboxes\auth\dataldr.box\BADMIFS" -Include *.MIF -Recurse | ?{$_.LastWriteTime -ge (Get-date).AddDays(-2)} | Measure-object
- Solution:
I231122_0361 : Console MECM on proxyadmin is inaccessible
Issue:
Console MECM on proxyadmin is inaccessible
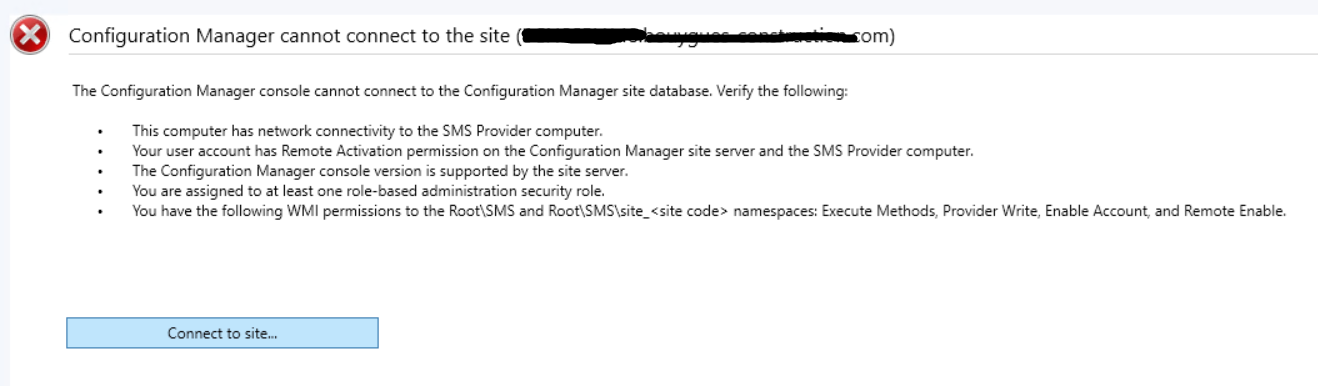
Solution:
Firewall rules for the server restored.
I231019_0230 : MCO - BADMIF exceed 300
Issue:
MCO - BADMIF exceed 300
Solution:
number of items normal. it isn’t normal if the number is greater than 5-10% of computers
Some other solutions
- Base sql plantée
- La base sql était plantée (cause veeam)
- Les serveurs ont été migrés sur vmware
- Si tu veux y accéder, soit t’ouvres une console MCM avec ton compte s1 et tu vas dans rapports
Soit par l’interface web, il faut lancer chrome par cyberark toujours avec ton compte s1 et tu vas sur https://sccmreport.bcc/reports et tu y as aussi (en remettant login/mdp de ton S1 car pas de SSO avec ces comptes) - Problem sql (saturation cpu). sauvegarde veeam modifiée et bascule always on pour rendre le service
- Réinstallation du client badgeprint test ok.
- Problème auto résolu, act mco d’aujourd’hui en PJ
- Problème résolu en faisant les manipulations suivantes : Vider le dossier Cache des téléchargements SCCM
Exécuter les cycles d’évaluation - Nouvelle version présente version 7.7 synchroniser vos policies dans le centre de logiciel “options dans maintenance de l’ordinateur” synchroniser la stratégie (mis…
- After restarting the server, values are back to normal:
La connexion doit se faire par cyberark en utilisant le compte Tier 2 (wXXX) - Si vous ne trouvez pas le client SCCM installé sur les postes , voici la procédure à suivre :
la réinstallation du client SCCM devrait se passer comme suit :- Télécharger le client depuis : http://xxxSSRV151.bcc.com/CCM_Client/ccmsetup.exe
- Copie le setup dans c:\temp
- Ouvrir CMD en Admin
- Exécuter la commande : c:\temp\ccmsetup.exe SMSSITECODE=PAP /forceinstall
Par la suite il faut vérifier que le dossier sous : c:\windows\ccm sont tous avec une date de création/modification qui date du jour de l’installation.
- Un redémarrage du poste est nécessaire par la suite, une fois fait il faut temporiser un peu le temps qu’il récupère les Policy cela peut prendre jusqu’à l’heure.
- Etat des lieux
- Logs transactionnels de la base de données CM_PAP à 2 T0
- Groupe AOAG xxxAOAG072 non synchronisé depuis le 06/06/2022 à 06H40 Jobs suivants non activés sur le serveur primaire du groupe AOAG xxxAOAG072 (source d’erreur : patch orchestrator SCO Windows Update 4/5/2022 : Action corrective à demander à Monsieur.M en cours) MaintenancePlan2016.DatabaseBackup - USER_DATABASES - LOGMaintenancePlan2016.DatabaseIntegrityCheck - ALL_DATABASESMaintenancePlan2016.IndexStatisticsOptimize - ALL_DATABASESMaintenancePlan2016.IndexStatisticsOptimize - CM_PAPMaintenancePlan2016.purge_history –> Logs transactionnels ont grossi démesurément
–> réactivation des logs sur le primaire xxxSDBA110 du groupe AOAG xxxAOAG072
MaintenancePlan2016.DatabaseBackup - USER_DATABASES - LOG n’a pas fonctionné depuis
Modification du job MaintenancePlan2016.DatabaseBackup - USER_DATABASES - LOG sur le serveur xxxSDBA111 pour que le job passe (Modification temporaire du paramètre @Directory)
Vérification du job et du groupe AOAG xxxAOAG072 et remise du job modifié à l’état initial.
Pour information :
pas de backup des bases de données depuis le 1er juin sur les serveurs xxxSDBA111 et xxxSDBA110.
Pour rappel les backup sont générés par une chaine $u (SCCM)- Autre source d’erreur :
Les jobs sql en erreur auraient doit être en erreur (En fait les instances SQL pour lesquelles les alertes SCOM se déclenchent sont incluses dans un groupe SCOM qui est alimenté via une expression régulière (PRD), ce qui n’est pas le cas des instances xxxSDBA110 et xxxSDBA111, d’où; le souci) Les backups générés par $u doivent être impérativement suivis. - La relance de chaine a été relance pour la date 02/06 et elle est terminé avec succès
- Une opération de mise a jour de SCMM (MCEM) est encours. C’est cette dernière qui est à la base de l’indisponibilité des applications
- Ci dessous la référence de l’opération: R220413_0018
- Correction apportée sur la TS new computer. Test validé par M